System Architecture & Audit Pipeline
Self-contained audit pipeline that converts ERP-style exports into audit-ready evidence: deterministic controls + optional FOIP/PII scanning + reproducible logs.
Produces exception tables (ghost vendors, PO variance, high-value flags) and optional FOIP/PII findings, saved as timestamped evidence files for review workflows.
1 System story
Procurement risk typically shows up in vendor integrity (ghost/shell vendors), invoice vs PO mismatches (variance/overbilling patterns), and unstructured Notes that can leak FOIP/PII. This system treats the export as a fact source and produces auditor-usable outputs: exceptions, evidence files, and reproducible logs.
2 End-to-end flow
The pipeline is designed to mirror a real internal audit workflow: generate ERP-like exports, apply deterministic controls, optionally scan Notes for privacy risk signals, and export evidence artifacts for review.
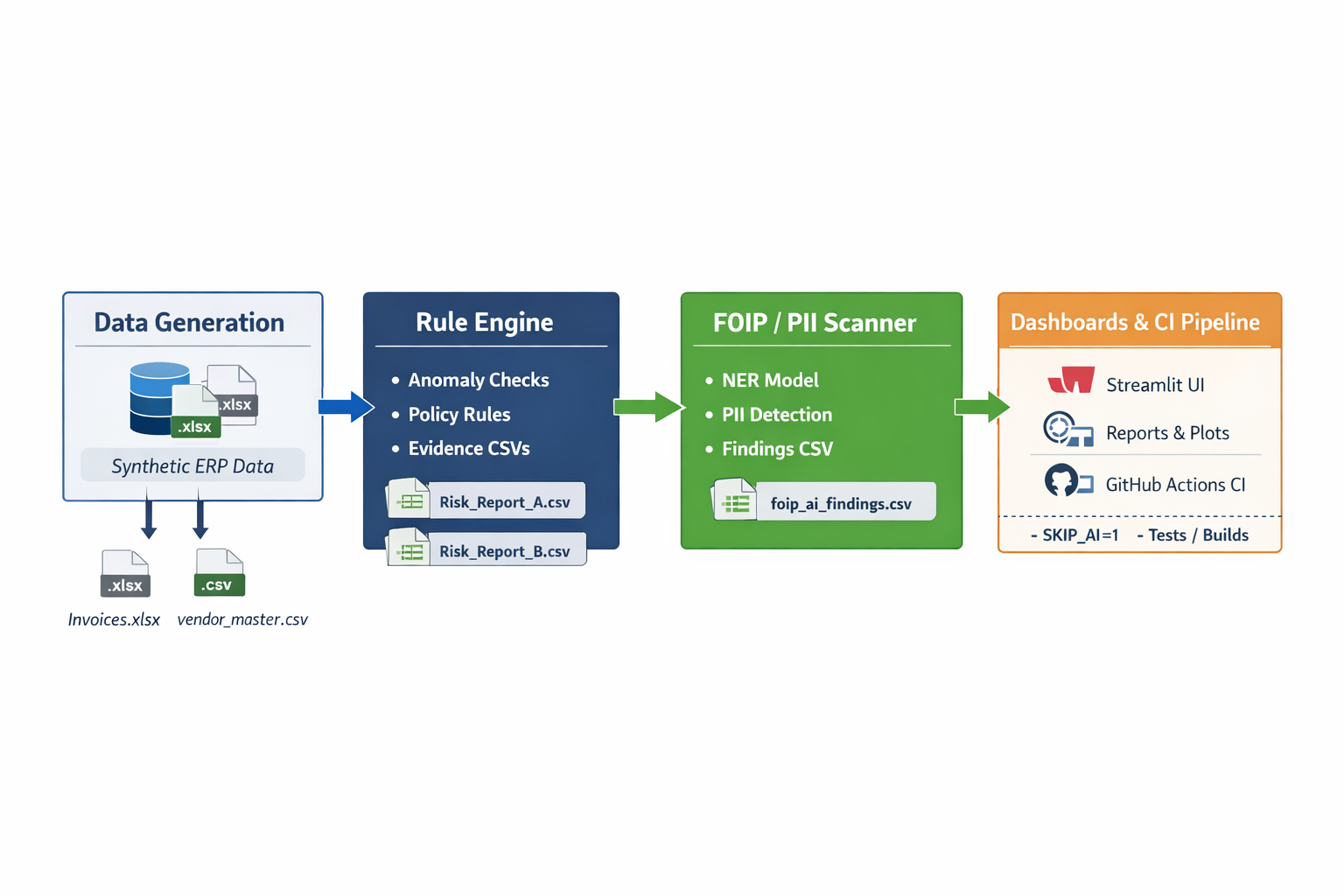
1) Data Generator creates a “dirty” ERP dump (
data/raw_erp_dump/invoices.xlsx
+
data/raw_erp_dump/vendor_master.csv
)
2) Rule Engine reads
config/audit_rules.yaml
and flags deterministic anomalies
3) AI Auditor scans unstructured Notes for FOIP/PII signals (optional in CI)
4) Evidence exports are written to
data/audit_reports/
(timestamped)
5) Streamlit Dashboard runs the audit and provides export buttons
6) CI runs the same flow but may skip AI for stability (SKIP_AI=1)
3 Components (what each part does)
Component: src/data_generator.py
Produces a safe, realistic dataset without using real ERP data.
data/raw_erp_dump/invoices.xlsx
data/raw_erp_dump/vendor_master.csv
: why synthetic data is non-negotiable
Real procurement exports often contain personal emails, names, phone numbers, and contract context. Synthetic data enables a public demo of FOIP/PII detection while keeping the pipeline reproducible and reviewable without privileged access.
Component: src/rule_engine.py
Deterministic, explainable checks using pandas. Thresholds live in YAML for change control.
• Ghost vendors (VendorID missing in master)
• PO variance (abs(invoice - po) / po above threshold)
• High-value invoice flags (policy threshold)
Evidence files are written to:
data/audit_reports/
(example outputs include ghost_vendors_YYYYMMDD_HHMMSS.csv, po_variance_YYYYMMDD_HHMMSS.csv, etc.)
: why YAML rules matter in real organizations
Audit thresholds change and controls are sometimes toggled during transitions. YAML makes policy readable to non-developers, version-controlled via diffs, and reduces hidden logic inside code—supporting a clean approval trail.
Component: src/ai_auditor.py
Flags privacy risk signals in unstructured text. Outputs evidence rows for human review.
Findings evidence is written to:
data/audit_reports/
(example: foip_ai_findings_YYYYMMDD_HHMMSS.csv)
: trust model — AI is assistive, not authoritative
Privacy/compliance workflows require human validation. The design stores the exact text snippet, the flags raised, and the invoice reference so a reviewer can verify context quickly.
Component: app/dashboard.py
One-screen UI: run audit, show pass/fail summary, inspect results, export evidence tables.
Sample mode loads from data/raw_erp_dump/. Upload mode accepts invoices and vendor master files directly through the UI.
Component: run_audit.sh
Single entry point that generates inputs, runs checks, exports evidence, runs tests, and writes logs.
CI validates deterministic controls and tests. AI can be skipped to avoid runner instability (downloads, torch/numpy mismatches). Local runs can include the full AI step.
: why the AI step is optional in CI
CI runners vary and model downloads can be flaky. The pipeline keeps deterministic controls and tests always-on, while AI analysis runs locally or in a controlled environment. This mirrors real compliance pipelines where stability comes first.
4 Trust boundaries & data handling
Only synthetic data is generated and stored. Evidence tables are safe to publish because they are derived from synthetic inputs (no real procurement data).
Rules are deterministic and repeatable. AI findings are triage signals for human review. Outputs include raw text evidence so reviewers can validate context.
Local runs demonstrate the full pipeline (including AI). CI runs prioritize stability and can skip AI using SKIP_AI=1.
5 Outputs (audit evidence map)
| Output Type | Where it lands | Why it matters |
|---|---|---|
| Raw inputs |
data/raw_erp_dump/
|
Reproducible “source” exports |
| Ghost vendors evidence |
data/audit_reports/
|
Vendor integrity exceptions |
| PO variance evidence |
data/audit_reports/
|
Overbilling / mismatch evidence |
| High value evidence |
data/audit_reports/
|
Review prioritization (materiality) |
| FOIP/PII findings |
data/audit_reports/
|
Privacy risk triage for review |
| Run logs |
data/audit_reports/run_logs/
|
Traceability, debugging, audit trail |
6 Scalability roadmap (production-grade direction)
Replace generator with secure connectors (export jobs, service accounts, approved access). Keep evidence artifacts unchanged.
Add phone/address patterns, stronger heuristics, and privacy-focused classifiers. Keep outputs as evidence-first exception lists.
Split rules into financial/vendor/approvals/delegation-limits. Keep YAML policy layer with versioned thresholds.
Persist runs to SQLite/Postgres with run IDs, evidence references, and metadata. Improves lineage and audit replay.
Dashboard authentication + restricted evidence exports to align with least privilege and internal compliance expectations.
Ship as a container for repeatable execution in standardized environments (local demo, controlled servers, enterprise runners).