Testing & CI Credibility (Reliability Story)
This project is intentionally built so the audit results are reproducible, and the core logic is testable without network access.
What “reliability” means here
- Deterministic rule checks (same inputs → same outputs).
- Evidence tables are materialized (CSV outputs become audit artifacts).
- AI scan is optional in CI (keeps CI fast + offline-safe), but fully available locally.
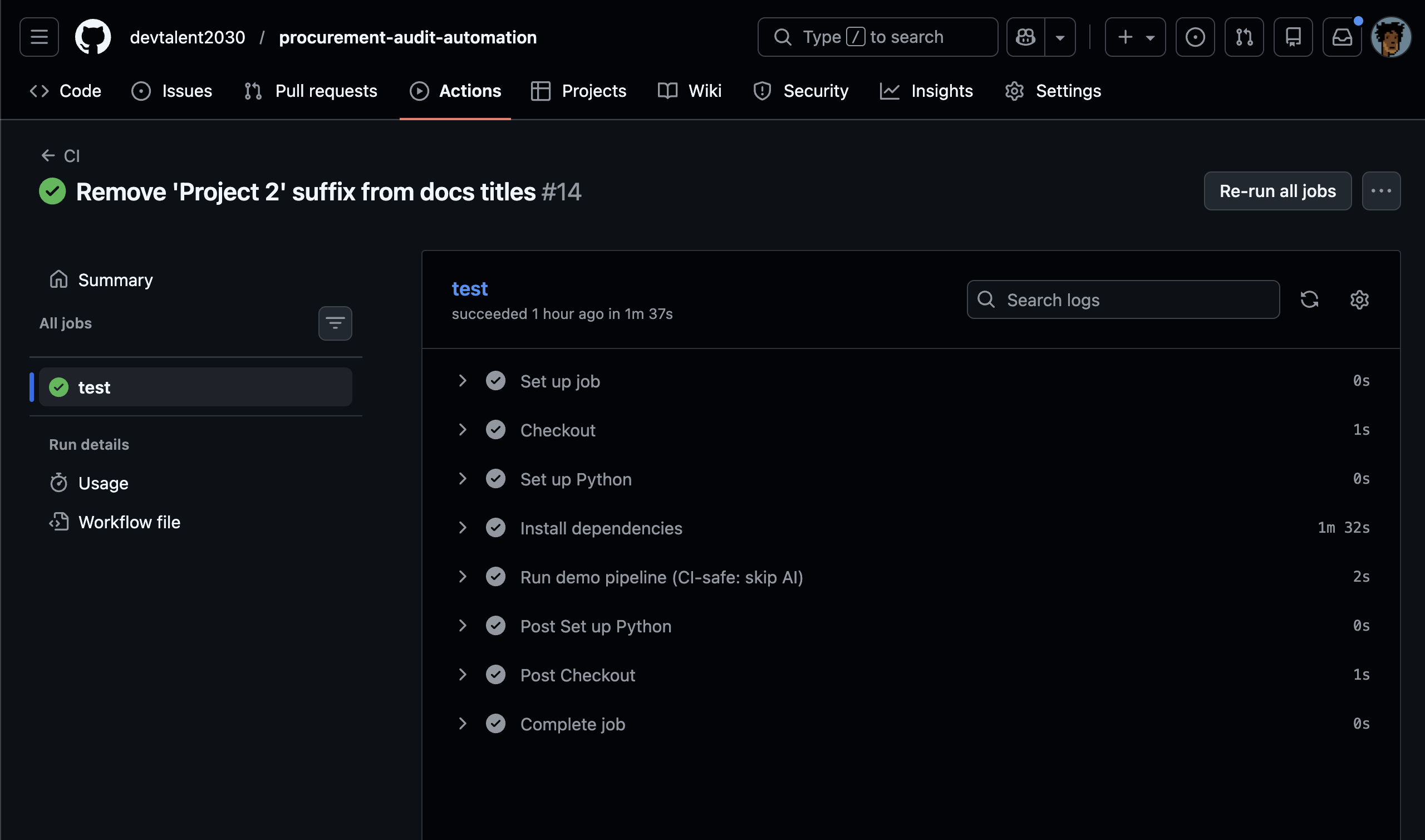
Screenshot proof of a green pipeline run.
Short clip showing ./run_audit.sh and the dashboard in action.
Test Suite Overview
The test suite is designed around a single principle:
Test the contract, not the environment.
Meaning:
- We verify what the functions produce (tables/flags/decisions).
- We avoid tests that depend on external services, model downloads, or machine-specific paths.
What is tested
| Area | What the test proves | Why it matters |
|---|---|---|
| Rule engine config | audit_rules.yaml is parsed correctly |
Prevents “silent misconfiguration” |
| Ghost vendor detection | Anti-join logic catches missing vendor IDs | Finds supplier master integrity issues |
| PO variance math | Variance threshold correctly flags outliers | Prevents overspend / mismatched PO alignment |
| FOIP/PII scan behavior | Name/email detection triggers as expected | Prevents privacy leaks in notes/comments |
| AI confidence threshold | Low-confidence entities don’t trigger false alerts | Reduces “privacy alert noise” |
What is mocked (and why)
HuggingFace model loading is mocked in unit tests
The AI scanner uses a NER pipeline (which normally may download weights). In tests, the pipeline is replaced with a fake predictable model.
This ensures:
- CI doesn’t require network access.
- Tests remain fast.
- We still validate the scanner’s decision logic.
What we mock:
load_auditor_brain()→ returns a predictable stub pipeline.
What we still test (real logic):
- confidence threshold behavior (e.g., recommended ~0.85)
- email heuristic behavior
- output schema (
InvoiceID,RiskContent,DetectedFlags)
Why CI skips AI by default (SKIP_AI)
CI should be:
- reliable (no flaky downloads)
- fast (minutes, not tens of minutes)
- repeatable (same outcome on any runner)
So the workflow uses an environment flag:
SKIP_AI=1→ skips the model-based scan in CI.- Local runs (developer machine) can run the full AI auditor normally.
This mirrors real enterprise practice:
- Production/analyst run: full scan with AI
- CI run: verify rule engine + scanner logic with deterministic stubs
GitHub Actions Pipeline
The CI pipeline validates the project in an “audit-friendly” order:
- Generate synthetic ERP-like data (so CI always has inputs)
- Run the deterministic rule engine
- Skip AI scan (by default) using
SKIP_AI=1 - Run unit tests (
pytest -q)
Evidence artifacts produced in CI
The pipeline outputs evidence CSVs (for screenshots / demo assets) and run logs:
data/audit_reports/*.csvdata/audit_reports/run_logs/*.log
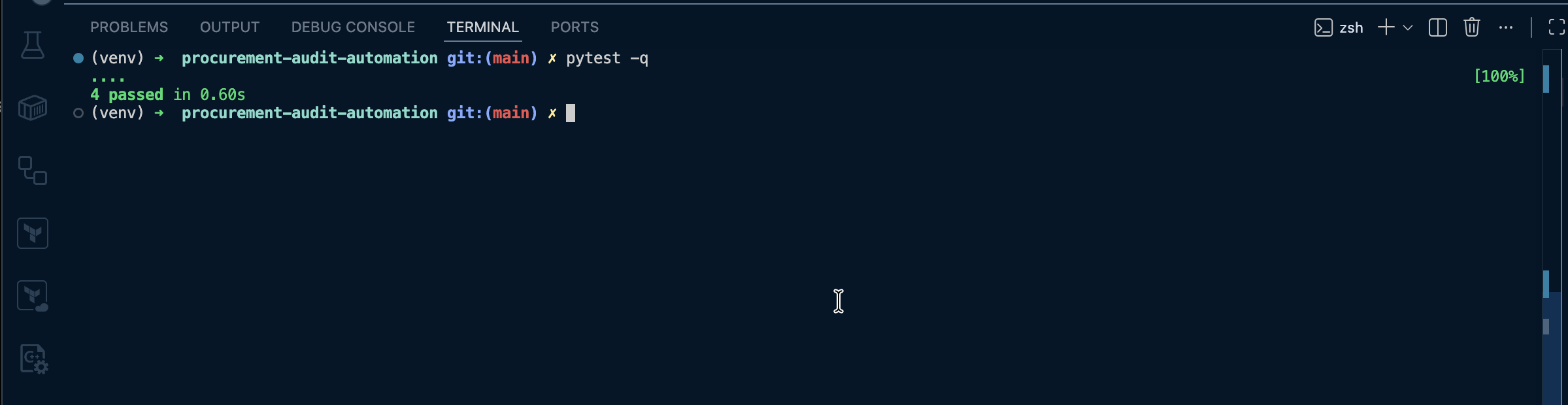
Local verification
Run tests
pytest -q
Run the full demo pipeline (includes AI unless you set SKIP_AI)
./run_audit.sh
Force skip AI locally (to simulate CI)
SKIP_AI=1 ./run_audit.sh
Known CI warning (and why it’s acceptable)
Some runners may show a PyTorch/NumPy warning (environment-specific). This does not affect the correctness of:
- rule engine outputs
- unit tests (AI brain is mocked)
If you ever choose to enable AI scanning in CI, this can be addressed by pinning compatible versions.
Quality gates (what “passing” means)
A green CI run means:
- Configuration parsing is correct
- Rule engine flags violations correctly
- AI scanner decision logic behaves correctly (mocked brain)
- Evidence tables are generated consistently